In this article, I am going to discuss the 5 Vs of Big Data. Please read our previous article, where we discussed What is Big Data and the history of Big Data in detail. At the end of this article, you will understand everything about the 5 Vs of Big Data in detail.

5 Vs of Big Data
In the year 2001, the analytics from the firm Gartner introduced 3Vs of data, which are Volume, Velocity, and Variety. Over a period of time, the data analytics field has seen dramatic changes where the collection started increasing from time to time. They named this type of data as big data and to handle this load of data 2Vs of data have been added. These 2Vs are Value and Veracity.
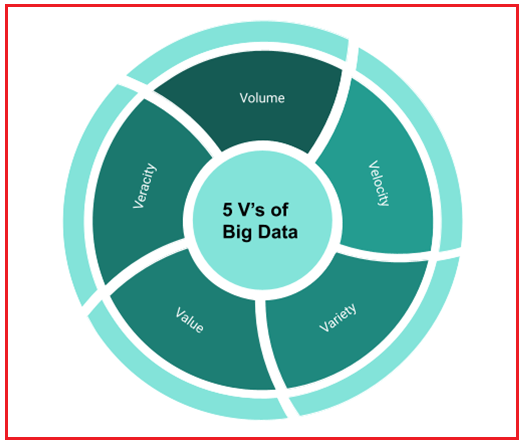
Following are the details of all 5 Vs:
1. Volume
Volume in Big data represents the amount of data. In todays world data is being processed in various formats like word, excel, pdf format, and sometimes in audio and video. These data can be structured or unstructured format. The recent social media platforms produce a tremendous amount of data which is difficult to handle by the organization. To handle this huge amount of data organizations should implement modern business intelligence tools which will capture this data in an effective form and which will be cost-efficient for the organization.
2. Velocity
Velocity refers to the increasing speed at which this data is created, so, the increasing speed at which the data can be processed, stored, and analyzed by relational databases. Imagine a machine learning service that is constantly learning from a stream of data, or a social media platform with billions of users posting and uploading photos 24×7. The speed at which data can be accessed has a direct impact on making timely and accurate business decisions. Even a limited amount of data that is available in real-time yields better business results than a large volume of data that needs a long time to capture and analyze.
It relates to the rate at which information is gathered. This is primarily due to the Internet of Things (IoT), mobile data, social media, and other factors. At least 2 trillion searches each year, 3.8 million searches per minute, 228 million searches per hour, and 5.6 billion searches per day are now being conducted.
3. Variety
The volume and velocity of data are important factors that add value to a business, big data also entails processing diverse data types collected from varied data sources. Data sources may involve external sources as well as internal business units. Data heterogeneity is often a source of stress in building up a data warehouse. Not only videos, photos, and highly hierarchically interconnected posts and tweets on social platforms but also basic user information can come in wildly different data types.
Due to various sources of data generated by humans or machines, it is categorized into Structured, Semi-structured, and Unstructured data.
- Structured data is traditional data that is ordered and adheres to a formal data structure. A bank statement, for example, would include the date, time, and amount.
- Data that is semi-structured is data that is not fully arranged. It deviates from the standard data structure. Log files, JSON files, CSV files, and so forth.
- Unstructured data is data that is not organized and does not fit into the rows and columns of a relational database. Text files, emails, photos, movies, voicemails, and audio files, for example.
4. Veracity
The Veracity of big data or Validity, as it is more commonly known, is the assurance of quality or credibility of the collected data. The data in the real world is so dynamic that it is hard to know what is right and what is wrong. Veracity refers to the level of trustiness or messiness of data, and if higher the trustiness of the data, then lower the messiness and vice versa.
It relates to the assurance of the datas quality, integrity, credibility, and accuracy. We must evaluate the data for accuracy before using it for business insights because it is obtained from multiple sources.
5. Value
In the context of big data, value amounts to how worthy the data is of positively impacting a companys business. It is very important to understand the cost of resources and effort invested in big data collection and how much value it provides at the end of the data processing. Value is very important because it is what runs the business by impacting business decisions and providing a competitive advantage.
It doesnt matter how much data we collect if we dont use it to gain any insights. The term “value†refers to how beneficial data is in making decisions. We must use good analytics to extract the value of Big Data.


